Kubernetes Network Troubleshooting
One of my favourite TV shows is Air Crash Investigation. This is a really insightful show that anyone with interest in engineering should watch. The TLDR of many of the episodes is lots of little problems ending in catastrophy.
In my little home network I’ve been having my own very minor calamity, so here are my notes of appoximately 4 months of weekend fixes to restore normal operation - saving here for posterity for the next time something breaks ;-)
Part I - Kubernetes problems
- Very poor throughput from Kubernetes TCP services hosted on MetalLB (packet loss, failed streaming)
- Longhorn - stuck replication, random crashes
Networking
Symptoms: connection reset ~70% of the time with L2 MetalLB services running on a HA Kubernetes cluster. Services are running and stable, ports are open, nc connects but try to read data and everything breaks.
Diagnosis
Run this handy script to check for good (.) vs dropped traffic (!)
#!/bin/bash
HOST=$1
PORT=$2
COLS=0
while true; do
if nc -zw 1 $HOST $PORT ; then
echo -n "."
else
echo -n "!"
fi
COLS=$(( COLS + 1 ))
if [ $(( COLS % 60 )) -eq 0 ]; then
echo
fi
done
Eliminate
- WIFI connected stations (power off)
- TCP dump ARP (used by MetalLB)
- On “Smart” switch - check that no ARP related options are selected, especially anything that mentions spoofing
- Much traffic is being generated by Longhorn continually rebuilding volumes - disable it
Cause
OpenWRT was dropping gratuatous ARPs. I had checked for this already but the option is on the Devices tab in the UI and I missed it:
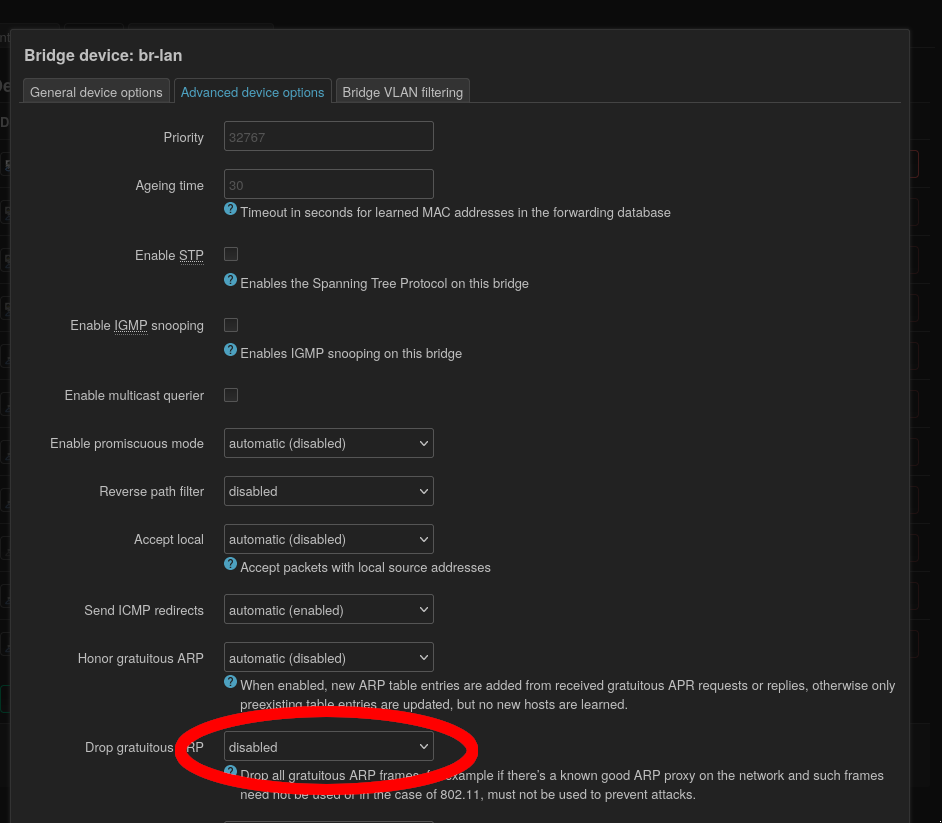
The corresponding config is option drop_gratuitous_arp '0'
Finally Kubernetes hosted services are working!
Part II - VM hosted services half-working
I moved Home Assistant from Kubernetes to a libvirt/KVM VM because it can only run on the Kubernetes node with the Zigbee controller and needs extensive network access to probe local devices. Since the move it did not work properly and seemed to be the last remaining service still experiencing network related problems. This was due to netfilter running on the bridge device. Disabling via /etc/sysctl.d/:
net.bridge.bridge-nf-call-ip6tables=0
net.bridge.bridge-nf-call-iptables=0
net.bridge.bridge-nf-call-arptables=0
Did not work properly because these rules were applied before br_netfilter loads on Debian 12, so the fix is to run a script on bootup:
#!/bin/bash
while ! lsmod | grep -q br_netfilter;
do
echo "br_netfilter not loaded yet... sleeping for 5 seconds"
sleep 5
done
echo "turning off firewall for bridge devices"
service procps force-reload
echo "reload complete"
sysctl net.bridge.bridge-nf-call-ip6tables
sysctl net.bridge.bridge-nf-call-iptables
sysctl net.bridge.bridge-nf-call-arptables
echo "exit"
Via Systemd service:
[Unit]
Description=Bridge configuration
After=network.target
[Service]
User=root
Type=oneshot
ExecStart=/usr/local/bin/bridge-config.sh
[Install]
WantedBy=multi-user.target
Part III - Hyper-V VM crashes
This one was fairly straight-forward: This PC only has a single NVMe slot so an extra one was added with a cheap PCI-e adaptor off Amazon to avoid accumulating more SATA hardware.
In Hyper-V this was exposed as a pass-through drive which resulted in OS level driver crashes inside Linux every few hours. Direct device attachment is the old-school way to add storage. Putting the drive back online and using regular disk image files on NTFS worked perfectly and stabilized the system - after spending several hours moving files between filesystems.
Part IV - Dead WIFI
WIFI just flat out stopped working on OpenWRT one day. Rebooting router would fix things temporarily and then boom - crashed. I can only suspect some kind of interference since nothing on the device had changed. Since my Router has a Broadcom chip, theres basically nothing that can be done to fix it - ever.
Luckily the month previous, I did some research on WIFI devices and settled on TP-Link Omada Access Points to setup a friends network in the countryside. I completely skipped the “prosumer” devices and went straight to full on commercial network gear.
Since I had a bunch of Raspberry Pis lying around, I wanted to run the Omada software controller on them instead of buying a dedicated hardware controller. This was somewhat involved, and long story short I wrote my own Raspberry PI OS for Omada: omadapi.
Since all this work had already been done to set my friend up, I was able to fix WIFI by just buying some Omada access points and hooking them up to Raspberry Pi - easy!
Part V - Memory upgrade
This was a saga on its own. With the VMs and Kubernetes now stable, I tried to add some more RAM to the Windows PC hosting the biggest Kubernetes node which resulted in it crashing after minutes/hours, hard-crashing all kubernetes nodes hosted on the PC.
TLDR: dont rely on BIOS to select usable memory timings
Part VI - Farewell Longhorn
As much as I like the idea of Longhorn and the longhorn UI, it had been stuck in a degraded state since the beginning of this drama several months ago and did not recover no matter what combination of rebooting/deploying/undeploying I came up with. I suspect my 1G network is just not fast enough. In the end I gave up and moved everything to Rook/Ceph - moving all data to Rook/Ceph gave me stable distributed storage.
Part VII - Tidying up network cables
With all these troubles fixed, last thing to do was tidy up the network cables by:
- Adding a TP-Link Omada Switch
- Moving the WIFI Access Point to the switch to run on PoE
- Link aggregation between this new switch and the existing “smart” switch
- Tidy up the damn cables
Getting all of this working was surprisingly tricky - mostly because of a missing feature in Omdada to have a “fully tagged” network port which meant return-path VLAN traffic to the WIFI access point was lost inside the smart switch.
With this fixed the last problem was I could not for the life of me get the TP-Link Smart Switch (TL-SG108PE) to work at all once LACP was turned on in Omada, even though it supported LAG and I had only one ethernet cable connected.
Turns out this is because Smart Switch (static) LAG != LACP. They are not compatible at all and the hashing algorithm used on the smart switch is not published either. Thankfully I had another Omada switch to hand and getting this working was as simple as swapping the switches around and enabling LACP.
Fixed!
Finally, with all this done and the cables tidied away and tagged I’m able to do some development work again!